
BrainWave
A note-taking app with a chat interface to find information in notes using AI and a specialized search index.
Role
Developer
- Timeline
- February 2024
Technologies
- Next.js
- Typescript
- TailwindCSS
- Prisma
- MongoDB
- Vercel AI
- ChatGPT API
- Pinecone
Tools
- GitHub
- Clerk
- Shadcn UI
Background
BrainWave was built to explore a more natural way to retrieve information from personal notes. Since traditional keyword search requires remembering exact phrasing, the project aimed to create a note-taking experience where users could ask questions in plain language. The goal was to develop a tool that understands the context of written content rather than just performing character matching.
Solution
The application uses a chat interface that connects to a specialized search index. When notes are created, the system generates a digital representation of the content, allowing it to be searched by meaning. Built with Next.js and secure authentication, the app ensures that personal notes remain private. The chat interface provides real-time feedback, creating a conversational experience for finding specific information.
Process
Development began with implementing core note management features such as entry creation and editing. Most of the work involved integrating the note database with an AI-powered search tool. This required developing a method to accurately transform text into searchable data and building a reliable retrieval system for the chat assistant. The interface was iteratively tested to ensure the chat felt responsive and effective during information retrieval.
Final Product
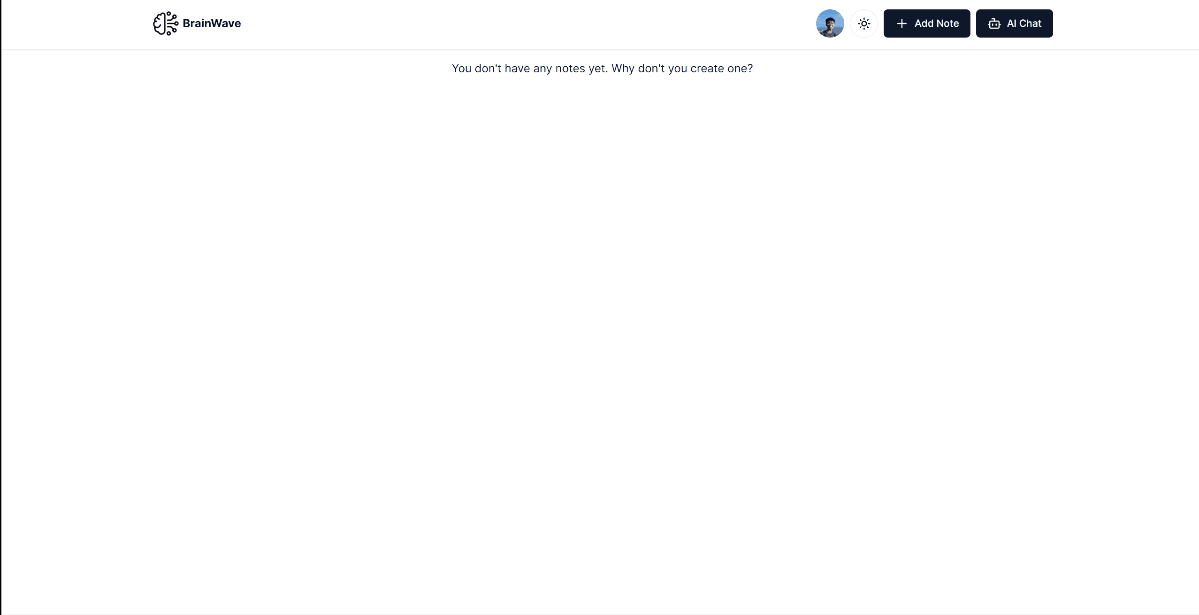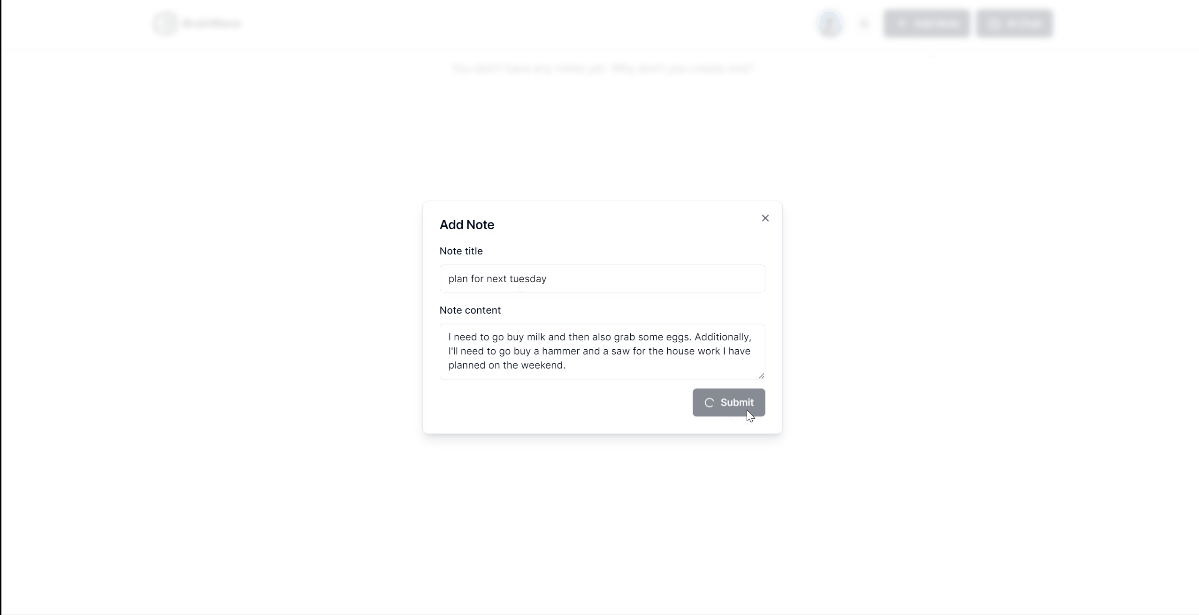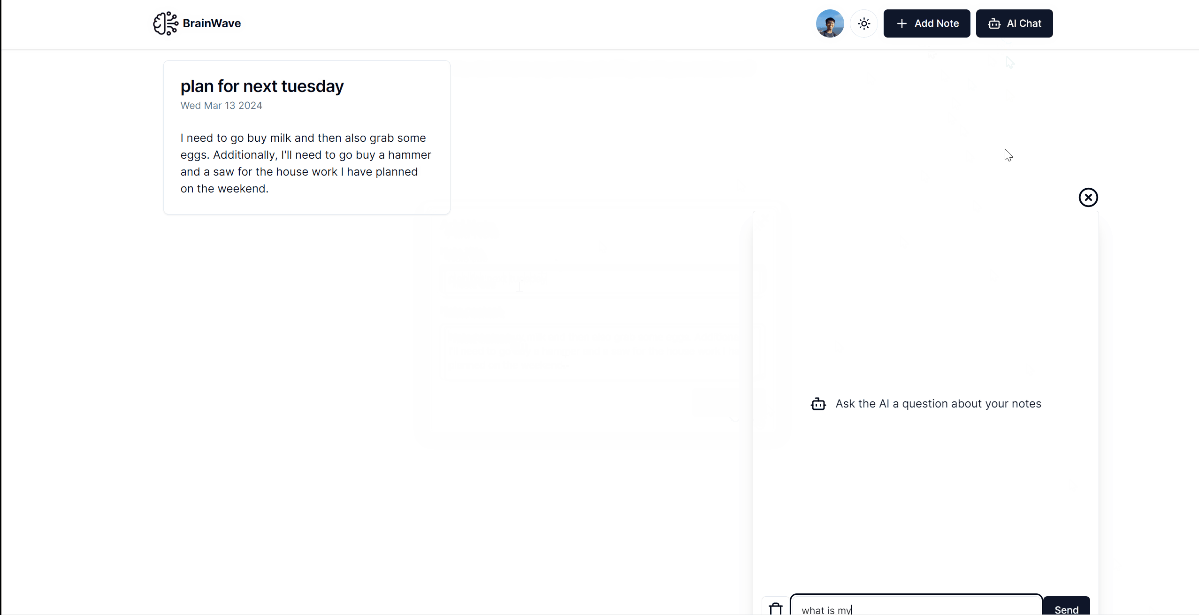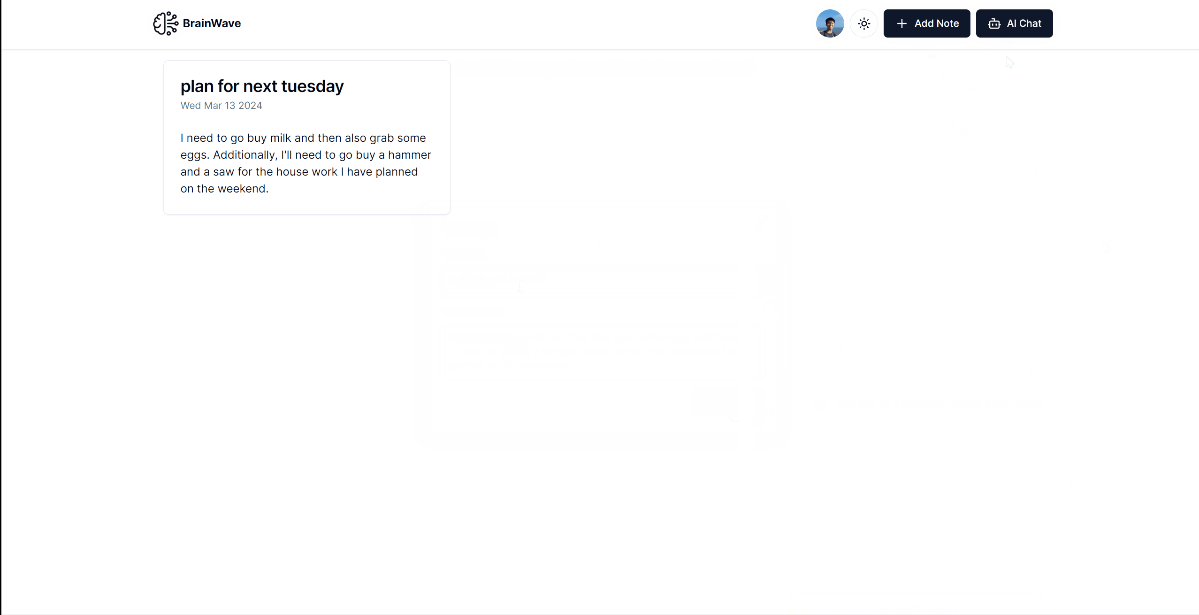
Impact
The project simplifies the process of retrieving information from large collections of notes. By allowing conversational queries, it reduces the time spent manually searching through old files. It serves as an exploration of how semantic search and AI patterns can improve the accessibility of personal data.
Reflection
Building BrainWave provided a lesson in coordinating multiple web services within a single application. The project required handling the data flow between a primary database and a search index without introducing unnecessary complexity. Future improvements could focus on increasing search accuracy and optimizing the system for even larger datasets.