Learning From Health
A project that uses health data to see if it can predict household income levels, exploring how health and economics are related.
Role
Developer
- Timeline
- January 2022
Technologies
- Python
- Pandas
- Matplotlib
- Seaborn
- Scikit-learn
Tools
- Jupyter Notebook
Background
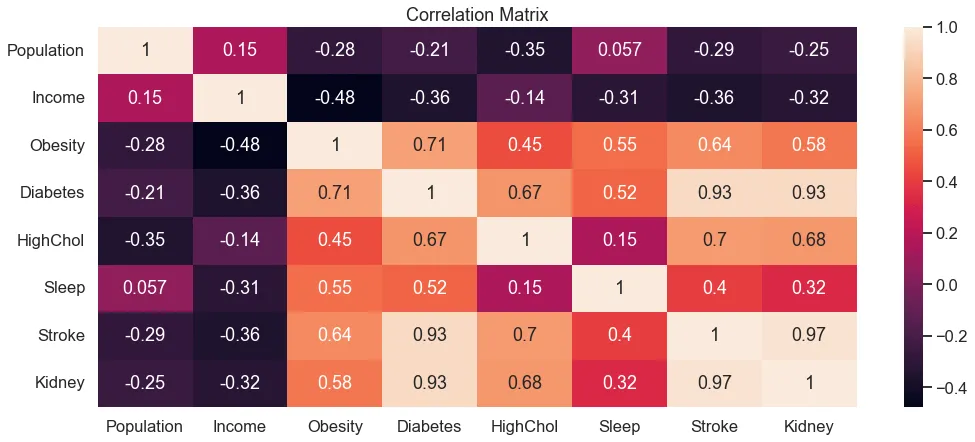
Learning From Health was created to explore the connection between health indicators and income levels. The project used real datasets from the CDC to see if conditions like diabetes or cholesterol could predict a person's economic status. It provided an opportunity to work with large-scale public health data to identify patterns between physical well-being and financial status.
Solution
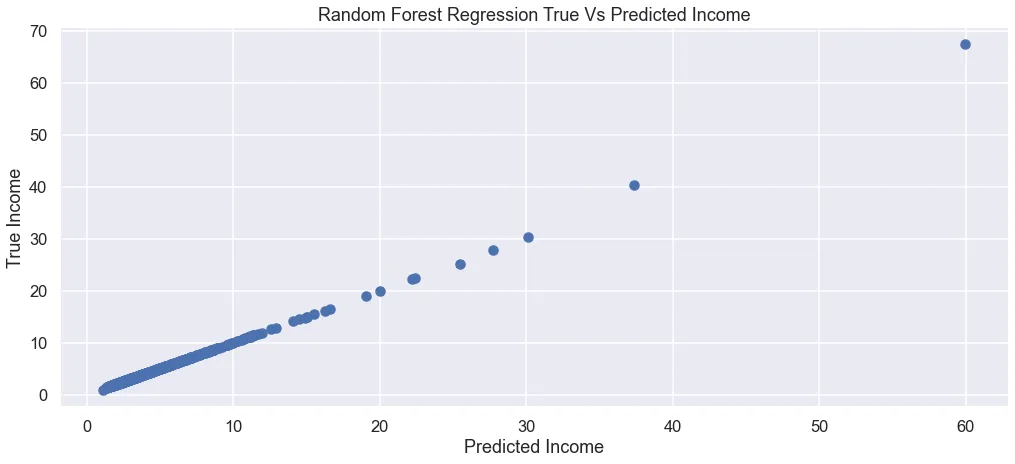
The analysis resulted in a predictive model that looks at health statistics and geographic data to estimate income. The model demonstrated a clear link between specific health conditions and earnings. Efforts were focused on data cleaning and visualization to make the relationships easier to understand, highlighting how factors like location influence the results.
Process
The process began with researching CDC health datasets and performing extensive data cleaning. Various charts and graphs were used to identify key features, followed by testing different modeling approaches. Once a reliable method was found, the findings were documented in a report to explain what the data revealed about the relationship between health and economics.
Final Product
Impact
The project identified a strong correlation between health indicators and economic status. It provided insights into how health issues vary across different regions and income levels, serving as a practical exploration of using data to understand complex public health challenges.
Reflection
Building this was an exercise in handling large datasets that contained missing or inconsistent information. It reinforced that data preparation is just as critical as the analysis model itself. While the current patterns are clear, future work could involve more diverse data to see if these trends remain consistent across a broader population.